文件/目录
ls 文件列表
1 | # -1 :每个文件展示一行 -l :展示全部信息(权限, 时间等, 首字母为文件类型: -:普通文件 d:文件夹 s:socket文件 l:链接文件) |
mkdir 建目录
1 | mkdir dir # 创建目录 |
rm 删除
1 | rm file # 删除前需要确认 |
cp 复制
1 | cp file1 path/ # 复制到目录, 保持文件名 |
mv 移动
1 | mv -i file1 file2 # 如果file2已存在则提示 |
chmod 改权限
ls -al输出类似-rw-r--r-- 1 root root 302108 11-13 06:03 xx.log的内容. 分三部分: 文件所属人的权限u, 文件所属组的权限g, 其他用户的权限o.
权限范围:
- u : 目录或文件的当前用户
- g : 目录或文件的当前群组
- o : 除了目录或文件的当前用户和群组之外的用户或者群组
- a : 所有的用户及群组
权限代号:
- r : 读权限, 用数字4表示
- w : 写权限, 用数字2表示
- x : 执行权限, 用数字1表示
- - : 删除权限, 用数字0表示
- s : 特殊权限
1 | chmod a+x file # 写法1, 所有人加执行权限 |
chown 改所属
1 | chown root file # 修改文件所属人 |
find 查找
1 | find -name "Hello.java" # 按名称在当前目录遍历查找 |
locate
1 | locate pwd # 类似find -name, 但该命令较快, 因为它是从数据库(/var/lib/locatedb)里查询, 可以使用updatedb命令更新数据 |
which
1 | which grep # 在PATH变量指定的路径中, 查询某个命令的位置, 并且返回第一个搜索结果 |
whereis
1 | # 只能搜索程序名, 而且只搜索二进制(-b), man文件(-m), 和源码(-s) |
type
1 | # 区分某个命令是否是shell自带的 |
sort
1 | # -f 忽略大小写, -C检查文件是否已排好序,如果乱序,不输出内容,仅返回1 |
uniq
1 | uniq -c # 显示重复次数 |
wc
1 | wc -l # 统计行数 |
realpath
readlink
文件内容
cat 读取内容
1 | cat file1 file2 # 顺序打印多个文件内容 |
grep 过滤
1 | grep "the" file |
tar 压缩包
1 | # -c :创建压缩文件; -x :解压压缩文件; -t :查看压缩文件 |
tail/head 头尾
1 | head file # 默认展示前10行 |
less/more 分段浏览
1 | # more只能往后看, less可以看后翻页 |
cut切分
sed 基于正则的流处理器
sed是一种在线编辑器, 每次处理一行内容. 处理时, 把当前行存储在临时缓冲区中, 称为”模式空间”(pattern space), 接着sed命令处理缓冲区中的内容. 处理完成后, 将缓冲区内容输出到屏幕. 然后接着处理下一行, 直至文件结束.
打印 p参数
1 | # 匹配fish并输出, 但是匹配到的行被输出了2遍, 这是因为sed会把待处理的信息也输出了 |
文本替换 s参数
1 | # 把一行上的每个(/g)单词 my 都替换成 your, 所有行都处理 |
地址表示法
| 表达式 | 说明 |
|---|---|
| n | 行号 |
| $ | 最后一行 |
| /regexp/ | 所有匹配该正则的文本行 |
| addr1,addr2 | 从addr1到addr2范围内的文本行, 包含addr2 |
| first~step | 从first行开始, 每个step的文本行, 例: 1~2值每个奇数行 |
| addr1,+n | 从addr1开始到后面的n行 |
| addr! | 除了addr之外的其他文本行 |
在行前插入一行 i参数
1 | # 在第一行前插入一行 This is a test line |
在行后插入一行 a参数
1 | # 在第一行后插入一行 This is a test line |
替换匹配行 c参数
1 | # 替换第二行 |
删除匹配行 d参数
1 | # 删除1到3行 |
命令打包
1 | # 对3到6行, 匹配到This就删除这一行 |
awk 格式化流处理器
1 | # 打印第1列和第3列 $0表示整行 |
过滤记录
1 | # 第3列等于0 且 第6列等于LISTEN 还有 != < <= > >= |
内建变量
| 变量名 | 说明 |
|---|---|
| $0 | 当前记录, 即整行内容 |
| $1 ~ $n | 当前记录的第n个字段, 字段间由FS分隔 |
| FS | 输入字段分隔符, 默认是空格或Tab |
| NF | 当前记录的字段个数, 即有多少列 |
| NR | 已经读出的记录数, 即行号, 从1开始, 如果有多个文件, 该值会不断累加 |
| FNR | 当前记录数, 与NR不同的是, 该值是各个文件自己的行号 |
| RS | 输入的记录分隔符, 默认为换行符 |
| OFS | 输入字段分隔符, 默认为空格 |
| ORS | 输出记录分隔符, 默认为换行符 |
| FILENAME | 当前输入文件的名称 |
1 | awk '$1=="tcp6" && $6=="LISTEN" {printf "%s %-20s %s\n", NR,$4,$5}' input.txt |
指定分隔符
1 | awk 'BEGIN{FS=":"} {print $1,$3,$6}' /etc/passwd |
字符串匹配
1 | # 过滤第6列匹配WAIT ~ 表示模式开始 //中是模式 |
拆分文件
1 | # 按第6列分隔文件 NR!=1表示不处理第一行 |
统计
1 | # 计算文件大小总和 |
awk脚本
语法如下:
- BEGIN{ 这里面放的是执行前的语句 }
- {这里面放的是处理每一行时要执行的语句}
- END {这里面放的是处理完所有的行后要执行的语句 }
示例
1 | $ cat score.txt |
环境变量
使用-v和ENVIRON与环境变量交互, 使用ENVIRON的环境变量需要export
1 | $ x=5 |
系统信息
uname
1 | uname -a # Linux host.localdomain 4.10.5-1.el6.elrepo.x86_64 #1 SMP Wed Mar 22 14:55:33 EDT 2017 x86_64 x86_64 x86_64 GNU/Linux |
passwd
存放用户信息:
/etc/passwd
/etc/shadow
存放组信息:
/etc/group
/etc/gshadow
用户文件信息组成:
例: jack:X:503:504:::/home/jack/:/bin/bash
jack //用户名
X //口令,密码
503 //用户id, 0代表root, 普通用户从500开始
504 //所在组
: //描述
/home/jack/ //用户的家目录
/bin/bash // 用户默认shell
组文件信息组成:
例: jack:$!$:???:13801:0:99999:7:::
jack // 组名
$!$ // 被加密的口令
13801 // 创建日期与今天相隔的天数
0 // 口令的最短位数
99999 // 用户口令
7 // 到7天时提醒
* // 禁用天数
* // 过期天数
1 | passwd # 命令行修改密码, 先输入旧的, 再输入新的 |
top 任务管理器
1 | $ top |
前5行为信息统计区:
- 16:41:15 - 系统当前时间; up 58 days, 4:44 - 运行时长, 期间没有重启过; 1user - 当前有1个用户登录; load average: 0.18, 0.23, 0.22 - 系统在过去1分钟, 5分钟, 15分钟的负载情况
- 系统当前有137个进程, 1个在运行, 136个在休眠, 0个停止, 0个僵尸态
- 1.3%us - 用户空间占用CPU的百分比; 0.6%sy - 内核空间占用CPU的百分比; 0.0%ni - 改变过优先级的进程占用CPU的百分比; 97.5%id - 空闲CPU百分比; 0.4%wa - IO等待占用CPU百分比; 0.0%hi - 硬中断(Hardware Interrunpt)占用CPU百分比; 0.2%st - 软中断占用CPU百分比
- 3918972k total - 物理内存总容量(4G); 3714896k used - 使用中的内存容量; 204076k free - 空闲的内存容量; 9192k buffers - 缓存的内存容量
- 2096440k total - 交换区总容量(2G); 59020k used - 使用的交换区容量; 2037420k free - 空闲的交换区容量; 194376k cached - 缓冲的交换区容量
- 空行
- 进程状态
- PID - 进程id
- USER - 进程所有者
- PR - 进程优先级
- NI - nice值, 负值表示高优先级, 正值表示低优先级
- VIRT - 进程使用的虚拟内存总量, 单位KB, VIRT=SWAP+RES
- RES - 进程使用的未被换出的物理内存大小, KB. RES=CODE+DATA
- SHR - 共享内存大小, KB.
- S - 进程状态
- %CPU - 上次更新到现在的CPU时间占用百分比
- %MEN - 进程使用的物理内存百分比
- TIME+ - 进程使用的CPU时间总计, 单位: 1/100秒
- COMMAND - 进程使用的命令
load average : 处理进程占CPU能力的百分比, 每隔5秒钟检查一次. 如果CPU每分钟最多处理100个进程,那么系统负荷0.2,意味着CPU在这1分钟里只处理了20个进程. 超过1说明有进程在排队等待CPU处理. 单CPU时负载大于0.7就需要注意了. 达到5时系统基本死机状态.
cat /proc/cpuinfo命令可查看CPU信息,grep -c 'model name' /proc/cpuinfo查看cpu核心数. 负载值不要超过核心数
应该关注15分钟的负载值, 1分钟的说明只是暂时现象
第四行中使用中的内存总量(used)指的是现在系统内核控制的内存数,空闲内存总量(free)是内核还未纳入其管控范围的数量。纳入内核管理的内存不见得都在使用中,还包括过去使用过的现在可以被重复利用的内存,内核并不把这些可被重新使用的内存交还到free中去,因此在linux上free内存会越来越少,但不用为此担心。
如果出于习惯去计算可用内存数,这里有个近似的计算公式:第四行的free + 第四行的buffers + 第五行的cached,按这个公式此台服务器的可用内存:18537836k +169884k +3612636k = 22GB左右。
对于内存监控,在top里我们要时刻监控第五行swap交换分区的used,如果这个数值在不断的变化,说明内核在不断进行内存和swap的数据交换,这是真正的内存不够用了。
查看线程
1 | top -H -p 1234 |
交互操作
q 退出top命令<Space> 立即刷新s 设置刷新时间间隔c 显示命令完全模式t 显示或隐藏进程和CPU状态信息m 显示或隐藏内存状态信息l 显示或隐藏uptime信息f 增加或减少进程显示标志S 累计模式,会把已完成或退出的子进程占用的CPU时间累计到父进程的MITE+P 按%CPU使用率排行T 按MITE+排行M 按%MEM排行u 指定显示用户进程r 修改进程renice值kkill 进程i 只显示正在运行的进程W 保存对top的设置到文件^/.toprc,下次启动将自动调用toprc文件的设置1 显示各逻辑CPU状况h 帮助命令
ps 查看进程
1 | # linux进程状态: 运行(R), 可中断的睡眠状态(S), 不可中断的睡眠状态(D), 僵尸(Z), 停止(T), 退出,即将被销毁(X) |
网络
iptables 防火墙
语法
1 | iptables(选项)(参数) |
选项
1 | -t, --table table 对指定的表 table 进行操作, table 必须是 raw, nat,filter,mangle 中的一个。如果不指定此选项,默认的是 filter 表。 |
基本参数
| 参数 | 作用 |
|---|---|
| -P | 设置默认策略:iptables -P INPUT (DROP |
| -F | 清空规则链 |
| -L | 查看规则链 |
| -A | 在规则链的末尾加入新规则 |
| -I | num 在规则链的头部加入新规则 |
| -D | num 删除某一条规则 |
| -s | 匹配来源地址IP/MASK,加叹号”!”表示除这个IP外。 |
| -d | 匹配目标地址 |
| -i | 网卡名称 匹配从这块网卡流入的数据 |
| -o | 网卡名称 匹配从这块网卡流出的数据 |
| -p | 匹配协议,如tcp,udp,icmp |
| –dport num | 匹配目标端口号 |
| –sport num | 匹配来源端口号 |
命令选项输入顺序
1 | iptables -t 表名 <-A/I/D/R> 规则链名 [规则号] <-i/o 网卡名> -p 协议名 <-s 源IP/源子网> --sport 源端口 <-d 目标IP/目标子网> --dport 目标端口 -j 动作 |
工作机制
规则链名包括(也被称为五个钩子函数(hook functions)):
- INPUT链 :处理输入数据包。
- OUTPUT链 :处理输出数据包。
- FORWARD链 :处理转发数据包。
- PREROUTING链 :用于目标地址转换(DNAT),内到外。
- POSTOUTING链 :用于源地址转换(SNAT),外到内。
防火墙策略
防火墙策略一般分为两种,一种叫通策略,一种叫堵策略,通策略,默认门是关着的,必须要定义谁能进。堵策略则是,大门是洞开的,但是你必须有身份认证,否则不能进。所以我们要定义,让进来的进来,让出去的出去,所以通,是要全通,而堵,则是要选择。当我们定义的策略的时候,要分别定义多条功能,其中:定义数据包中允许或者不允许的策略,filter过滤的功能,而定义地址转换的功能的则是nat选项。为了让这些功能交替工作,我们制定出了“表”这个定义,来定义、区分各种不同的工作功能和处理方式。
现在用的比较多个功能有3个:
- filter 定义允许或者不允许的,只能做在3个链上:INPUT ,FORWARD ,OUTPUT
- nat 定义地址转换的,也只能做在3个链上:PREROUTING ,OUTPUT ,POSTROUTING
- mangle功能:修改报文原数据,是5个链都可以做:PREROUTING,INPUT,FORWARD,OUTPUT,POSTROUTING
我们修改报文原数据就是来修改TTL的。能够实现将数据包的元数据拆开,在里面做标记/修改内容的。而防火墙标记,其实就是靠mangle来实现的。
表名包括:
- raw :RAW表只使用在PREROUTING链和OUTPUT链上,因为优先级最高,从而可以对收到的数据包在连接跟踪前进行处理。一但用户使用了RAW表,在某个链上,RAW表处理完后,将跳过NAT表和ip_conntrack处理,即不再做地址转换和数据包的链接跟踪处理了.
- mangle :拥有prerouting、FORWARD、postrouting三个规则链,除了进行网址转译工作会改写封包外,在某些特殊应用可能也必须去改写封包(ITL、TOS)或者是设定MARK(将封包作记号,以进行后续的过滤)这时就必须将这些工作定义在mangles规则表中
- nat :拥有prerouting和postrouting两个规则链, 主要功能为进行一对一、一对多、多对多等网址转译工作(SNATDNAT)用于网关路由器。
- filter :预设规则表,拥有 INPUT、FORWARD 和 OUTPUT 三个规则链,这个规则表顾名思义是用来进行封包过滤的理动作
4个表的优先级由高到低:raw–>mangle–>nat–>filter
动作包括:
ACCEPT :接收数据包。
DROP :丢弃数据包。
REDIRECT :重定向、映射、透明代理。
SNAT :源地址转换。
DNAT :目标地址转换。
MASQUERADE :IP伪装(NAT),用于ADSL。
LOG :日志记录。
SEMARK : 添加SEMARK标记以供网域内强制访问控制(MAC)
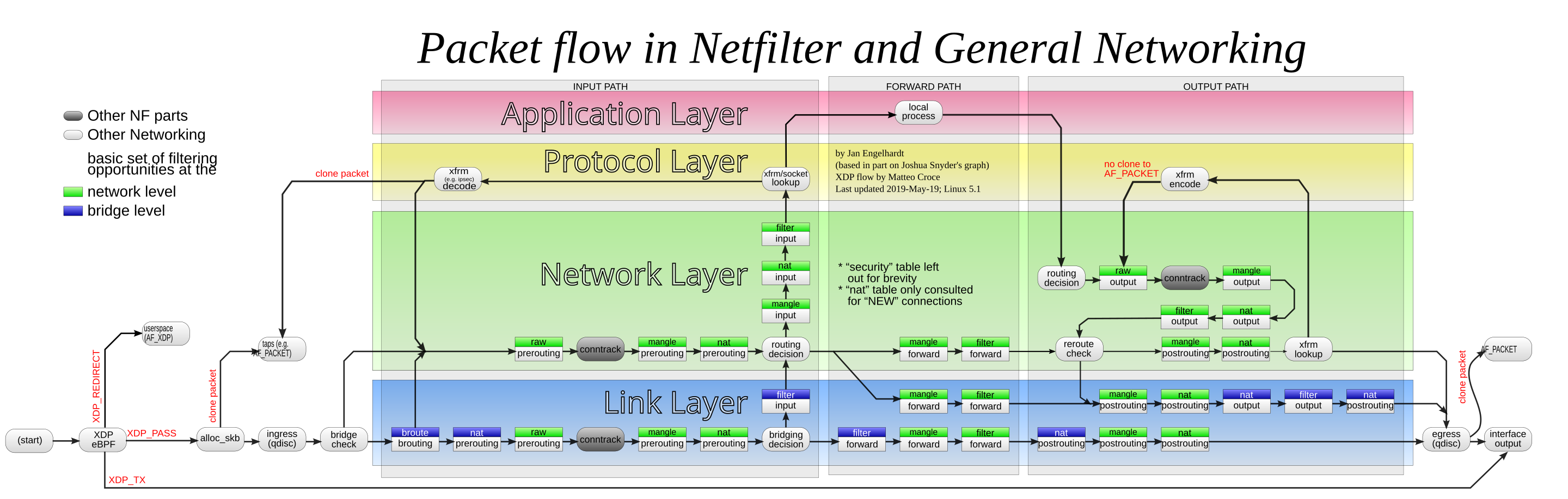
实例
清空当前的所有规则和计数
1 | iptables -F # 清空所有的防火墙规则 |
配置允许ssh端口连接
1 | iptables -A INPUT -s 192.168.1.0/24 -p tcp --dport 22 -j ACCEPT |
允许本地回环地址可以正常使用
1 | iptables -A INPUT -i lo -j ACCEPT |
设置默认的规则
1 | iptables -P INPUT DROP # 配置默认的不让进 |
配置白名单
1 | iptables -A INPUT -p all -s 192.168.1.0/24 -j ACCEPT # 允许机房内网机器可以访问 |
开启相应的服务端口
1 | iptables -A INPUT -p tcp --dport 80 -j ACCEPT # 开启80端口,因为web对外都是这个端口 |
保存规则到配置文件中
1 | # 任何改动之前先备份,请保持这一优秀的习惯 |
列出已设置的规则
1 | iptables -L -t nat # 列出 nat 上面的所有规则 |
删除已添加的规则
1 | # 添加一条规则 |
开放指定的端口
1 | iptables -A INPUT -s 127.0.0.1 -d 127.0.0.1 -j ACCEPT #允许本地回环接口(即运行本机访问本机) |
屏蔽IP
1 | iptables -A INPUT -p tcp -m tcp -s 192.168.0.8 -j DROP # 屏蔽恶意主机(比如,192.168.0.8 |
指定数据包出去的网络接口
1 | # 只对 OUTPUT,FORWARD,POSTROUTING 三个链起作用 |
端口映射
1 | # 本机的 2222 端口映射到内网 虚拟机的22 端口 |
firewalld
1 | # 安装firewalld |
配置
1 | firewall-cmd --version # 查看版本 |
服务管理
1 | # 显示服务列表 |
端口管理
1 | firewall-cmd --add-port=443/tcp # 打开443/TCP端口 |
ping 测试网络通断与延迟
1 | ping www.baidu.com |
tcpping
ping命令是基于ICMP协议, 遇到某些主机会禁用ICMP协议导致Ping命令失效, 这时可以使用基于tcp协议的工具, 比如: tcpping, tcping, psping, hping, paping等
tcpping安装步骤如下:
1 | # 1. tcpping 脚本依赖 tcptraceroute 组件, 所以必须先安装 tcptraceroute |
hping是一个命令行下使用的 TCP/IP 数据包组装/分析工具, 它不仅能发送 ICMP 回应请求, 它还可以支持 TCP、UDP、ICMP 和 RAW-IP 协议
1 | # 安装 |
ifconfig 网络管理
1 | # 显示网络设备信息(激活状态的) |
nmcli 网络管理
安装命令:yum install -y NetworkManager, centos默认已安装
1 | # 网络设备列表及其状态 |
IP 网络配置
1 | # 显示网络接口信息 |
netstat
1 | netstat -natp | grep 3306 |
- -a (all)显示所有选项,默认不显示 LISTEN 相关
- -t (tcp)仅显示 tcp 相关选项
- -u (udp)仅显示 udp 相关选项
- -n 拒绝显示别名,能显示数字的全部转化成数字。
- -l 仅列出有在 Listen (监听) 的服務状态
- -p 显示建立相关链接的程序名
- -r 显示路由信息,路由表
- -e 显示扩展信息,例如 uid 等
- -s 按各个协议进行统计
- -c 每隔一个固定时间,执行该 netstat 命令。
我们常说的丢包有三种:
- 一种是内核能够记录的,也就是协议栈上的丢包;
- 另一种是网卡能够记录的,就是网卡处理不过来丢包;
- 第三种就是传输过程中被丢弃的,也就是离开本机之后,未能到达目标主机的。
不管哪种丢包,根据TCP协议的重传规则,我们都可以通过重传来估算系统的丢包情况:
1 | $ netstat -st | grep retrans |
查看全队列配置情况
1 | $ netstat -st | grep SYN |
如果xx times the listen queue of a socket overflowed 和 xx SYNs to LISTEN sockets dropped出现持续的增长, 说明服务器的全队列过小, 全队列发生溢出, 后续的请求就会被丢弃, 服务端出现请求数量上不去的现象.
查看所有端口的统计信息,-st/-su:统计TCP/UDP
1 | $ netstat -s |
通常我们可以通过查找 netstat -s 中 overrun、 collapse、pruned 等事件来观察,如果相关的统计项一直都在增长,那么说明应用的接收缓冲区需要调整了
ss - 网络
1 | # 显示所有TCP连接 |
-a显示所有套接字-l显示监听状态的套接字-s显示套接字使用概况-t仅显示tcp连接,-u仅显示udp连接-4仅显示IPv4套接字-6仅显示IPv6套接字-p显示使用该套接字的进程信息, 会显示进程命令/进程id/文件描述符-m显示套接字的内存使用情况-e显示详细的套接字信息-i显示TCP内部信息-r解析主机名-n不解析服务名称(不加的话不显示端口, 而是显示服务名)
TCP 半连接队列和全连接队列满了会发生什么?又该如何应对?
lsof 一切皆文件
用于查看打开文件的进程, 进程打开了哪些文件, 端口等. 由于lsof命令需要访问核心内存和各种文件, 所以需要root用户执行.
1 | $ lsof /iflytek/server/jdk1.8.0_71/bin/java |
COMMAND : 进程名称 PID : 进程id USER : 进程所有者 FD : 文件描述符 TYPE : 文件类型 DEVICE: 磁盘名称 SIZE : 文件大小 NODE : 索引节点(文件在磁盘上的标识) NAME : 被打开文件的确切名称
1 | # 查询某个用户打开的文件 |
sftp
连接命令格式:
1 | sftp user_name@remote_server_address[:远程路径] |
其他参数:
- -B: buffer size, 设置传输buffer大小, 默认为32768
- -p: 当服务器自定义了连接的端口号是, 使用
-p指定端口号 - -R: 默认64, 提高该值贵略微提高传输速度, 但会消耗更多内存
连接后, 执行的bash命令, 默认是操作服务器的, 如果要操作本地环境, 则需要在命令前加上字符l.
1 | pwd |
文件传输
从服务器拉取
1
2
3
4
5# 如果不指定newName, 则下载的文件和服务器的文件同名
sftp> get remoteFile [newName]
# 拉取目录
sftp> get -r remoteDirectory
从本地上传
1
2
3
4
5sftp> put localFile
# 上传目录, 如果服务器不存在该目录则需要先创建
sftp> mkdir folderName
sftp> put -r folderName
ethtool 网卡信息查看
1 | [root@jzcpx-no ~]# ethtool enp95s0f0 |
Speed: 10000Mb/s 万兆网卡, 最大1.22GB/s
nslookup 查询DNS记录
1 | $ nslookup www.baidu.com |
dig 查询DNS解析过程
1 | $ dig baidu.com |
tcpdump 抓包
抓取经过eth0接口请求8080端口的tcp请求
1 | tcpdump tcp -i eth0 -s 0 -nn -vvv and port 8080 -w tcpdump.cap |
- 类型:
hostnetport - 方向:
srcdstsrc or dstsrc and dst - 协议:
iptcpudparpicmp….
1 | # 实时查看 |
tcp: tcp udp ip ip6 icmp arp等这些选项都要放到第一个参数的位置,用来过滤数据报的类型-i eth0:只抓取接口eth0的包-s 0:默认只抓取68字节,加上-s 0后可以抓取完整的数据包-c 100:只抓取100个数据包dst port ! 22:不抓取目标端口是22的数据包src net 192.168.1.0/24:数据包的源网络地址为192.168.1.0/24-w tcpdump.pcap:抓取结果写入文件-X:以16进制和ASCII码显示包数据,现场分析数据包内容必备-e: 显示数据链路层信息, 显示mac地址已经vlan信息-p: 不进入混杂模式, 屏蔽交换机在混杂模式下的噪声, 只接受给自己的数据, 不能与host或broadcast一起使用
常见的 TCP 报文的 Flags:
[S]: SYN(开始连接)[.]: 没有 Flag[P]: PSH(推送数据)[F]: FIN (结束连接)[R]: RST(重置连接)
设置不解析域名提示速度
-n:将IP以数字形式显示,否则显示为主机名-nn:除了有-n的作用,还把端口显示为数值,否则显示为端口服务名-N:不打印host的域名部分
控制详细内容的输出
-v:产生详细的输出. 比如包的TTL,id标识,数据包长度,以及IP包的一些选项。同时它还会打开一些附加的包完整性检测,比如对IP或ICMP包头部的校验和。-vv:产生比-v更详细的输出. 比如NFS回应包中的附加域将会被打印, SMB数据包也会被完全解码。(摘自网络,目前我还未使用过)-vvv:产生比-vv更详细的输出。比如 telent 时所使用的SB, SE 选项将会被打印, 如果telnet同时使用的是图形界面,其相应的图形选项将会以16进制的方式打印出来(摘自网络,目前我还未使用过)
控制时间的显示
-t:在每行的输出中不输出时间-tt:在每行的输出中会输出时间戳(相对1970-01-01)-ttt:输出每两行的时间间隔(以毫秒为单位)-tttt:在每行的时间戳之前添加日期(此种选项,输出的时间最直观)
显示数据包的头部
-x:以16进制的形式打印每个包的头部数据(但不包括数据链路层的头部)-xx:以16进制的形式打印每个包的头部数据(包括数据链路层的头部)-X:以16进制和 ASCII码形式打印出每个包的数据(但不包括连接层的头部),这在分析一些新协议的数据包很方便。-XX:以16进制和 ASCII码形式打印出每个包的数据(包括连接层的头部),这在分析一些新协议的数据包很方便。
对输出内容进行控制的参数
-D: 显示所有可用网络接口的列表-e: 每行的打印输出中将包括数据包的数据链路层头部信息-E: 揭秘IPSEC数据-L:列出指定网络接口所支持的数据链路层的类型后退出-Z:后接用户名,在抓包时会受到权限的限制。如果以root用户启动tcpdump,tcpdump将会有超级用户权限。-d:打印出易读的包匹配码-dd:以C语言的形式打印出包匹配码.-ddd:以十进制数的形式打印出包匹配码
过滤特定流向的数据包
-Q: 选择是入方向还是出方向的数据包,可选项有:in, out, inout,也可以使用 –direction=[direction] 这种写法
其他参数
-A:以ASCII码方式显示每一个数据包(不显示链路层头部信息). 在抓取包含网页数据的数据包时, 可方便查看数据-l: 基于行的输出,便于你保存查看,或者交给其它工具分析-q: 简洁地打印输出。即打印很少的协议相关信息, 从而输出行都比较简短.-c: 捕获 count 个包 tcpdump 就退出-s: tcpdump 默认只会截取前96字节的内容,要想截取所有的报文内容,可以使用-s number,number就是你要截取的报文字节数,如果是 0 的话,表示截取报文全部内容。-S: 使用绝对序列号,而不是相对序列号-C:file-size,tcpdump 在把原始数据包直接保存到文件中之前, 检查此文件大小是否超过file-size. 如果超过了, 将关闭此文件,另创一个文件继续用于原始数据包的记录. 新创建的文件名与-w 选项指定的文件名一致, 但文件名后多了一个数字.该数字会从1开始随着新创建文件的增多而增加. file-size的单位是百万字节(nt: 这里指1,000,000个字节,并非1,048,576个字节, 后者是以1024字节为1k, 1024k字节为1M计算所得, 即1M=1024 * 1024 = 1,048,576)-F:使用file 文件作为过滤条件表达式的输入, 此时命令行上的输入将被
1 | # 监听特定网卡 |
wireshark 使用
通常 Wireshark(或 tshark)比 tcpdump 更容易分析应用层协议。一般的做法是在远程服务器上先使用 tcpdump 抓取数据并写入文件,然后再将文件拷贝到本地工作站上用 Wireshark 分析。
还有一种更高效的方法,可以通过 ssh 连接将抓取到的数据实时发送给 Wireshark 进行分析。
1 | 使用wireshark实时分析 |
过滤器语法
根据IP过滤
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17# ip过滤
ip.addr == 10.43.54.65
# 等同于
ip.src == 10.43.54.65 or ip.dst == 10.43.54.65
ip.addr != 10.43.54.65
# 等同于
ip.src != 10.43.54.65 or ip.dst != 10.43.54.65
!(ip.addr == 10.43.54.65)
# 等同于 这个更常用
!(ip.src == 10.43.54.65 or ip.dst == 10.43.54.65)
# 网段过滤
ip.src==192.168.0.0/16 and ip.dst==192.168.0.0/16
ip.addr in {10.0.0.5 .. 10.0.0.9 192.168.1.1..192.168.1.9}根据端口过滤
1
2
3
4
5tcp.port == 25
tcp.port in {80 443 8080}
tcp.port == 443 || (tcp.port >= 4430 && tcp.port <= 4434)
tcp.dstport == 23
tcp.srcport == 23HTTP协议过滤
1
2
3
4
5
6
7
8
9
10
11
12
13
14# 主机过滤
http.host == "www.baidu.com"
http contains "HTTP/1.1 200 OK" && http contains "application/json"
# 其他常用条件
http.accept
http.location
http.request.method
http.request.uri
http.response.code
http.server
http.referer
# http uri结尾字符
http.request.uri matches "gl=se$"根据MAC过滤
1
2
3eth.dst == A0:00:00:04:C5:84 // 过滤目标mac
eth.src eq A0:00:00:04:C5:84 // 过滤来源mac
eth.addr eq A0:00:00:04:C5:84 // 过滤来源MAC和目标MAC都等于A0:00:00:04:C5:84的
wget 文件下载
1 | wget -O file www.xx.com # 保存到指定文件 |
curl
1 | # GET www.xx.com/search?a=aa&b=bb |
scp 远程拷贝
1 | # 从远程拷贝回本地 |
文件传输RZ、SZ
xshell下可以使用,只适合小的文件传输
1 | # 安装 |
mount 磁盘挂载
1 | # 列出文件系统的整体磁盘空间使用情况 |
这里以CentOS下创建xfs为例
centos7.0开始默认文件系统是xfs,centos6是ext4,centos5是ext3
1 | # 1 安装XFS系统工具集 |
查看磁盘分区的文件系统类型
1 | $ df -Th |
LVM(Logical volume Manager)逻辑卷管理相关概念
传统的磁盘管理机制,Linux操作系统和windows的差不多,绝大多数都是使用MBR(Master Boot Recorder)都是通过先对一个硬盘进行分区,然后再将该分区进行文件系统的格式化,在Linux系统中如果要使用该分区就将其挂载上去即可,windows的话其实底层也就是自动将所有的分区挂载好,然后我们就可以对该分区进行使用了。
在传统的磁盘管理机制中,我们的上层应用是直接访问文件系统,从而对底层的物理硬盘进行读取,而在LVM中,其通过对底层的硬盘进行封装,当我们对底层的物理硬盘进行操作时,其不再是针对于分区进行操作,而是通过一个叫做逻辑卷的东西来对其进行底层的磁盘管理操作。
LVM最大的特点就是可以对磁盘进行动态管理。因为逻辑卷的大小是可以动态调整的,而且不会丢失现有的数据。我们如果新增加了硬盘,其也不会改变现有上层的逻辑卷。
- 物理拓展(Physical Extend,PE)
- 物理卷(Physical Volume,PV):也就是物理磁盘分区,如果想要使用LVM来管理这个分区,可以使用fdisk将其ID改为LVM可以识别的值,即8e。
- 卷组(Volume Group,VG):PV的集合
- 逻辑卷(Logic Volume,LV):VG中画出来的一块逻辑磁盘
为什么要使用逻辑卷:
- 业务上使用大容量的磁盘。举个例子,我们需要在/data下挂载30TB的存储,对于单个磁盘,是无法满足要求的,因为市面上没有那么大的单块磁盘。但是如果我们使用逻辑卷,将多个小容量的磁盘聚合为一个大的逻辑磁盘,就能满足需求。
- 扩展和收缩磁盘。在业务初期规划磁盘时,我们并不能完全知道需要分配多少磁盘空间是合理的,如果使用物理卷,后期无法扩展和收缩,如果使用逻辑卷,可以根据后期的需求量,手动扩展或收缩。
总结:
(1)物理磁盘被格式化为PV,空间被划分为一个个的PE
(2)不同的PV加入到同一个VG中,不同PV的PE全部进入到了VG的PE池内
(3)LV基于PE创建,大小为PE的整数倍,组成LV的PE可能来自不同的物理磁盘(当我们创建好我们的VG以后,这个时候我们创建LV其实就是从VG中拿出我们指定数量的PE)
(4)LV现在就直接可以格式化后挂载使用了
(5)LV的扩充缩减实际上就是增加或减少组成该LV的PE数量,其过程不会丢失原始数据
time 统计命令执行时间
1 | $ time ps axu |
real挂钟时间, 即命令从开始到结束的时间, 包括其他进程所占用的时间片和进程被阻塞所花费的时间user花费在用户模式中的CPU时间, 这是唯一真正用于执行进程所花费的时间, 其他进程和阻塞时间不算在内sys花费在内核模式中的CPU时间, 代表在内核中执行系统调用所花费的时间, 这也是真正由进程使用的CPU时间
date 系统时间
1 | date |
修改时间、时区、语言
1 | # 查看当前时区 |
1 | # 查看时间日期 |
1 | # 查看当前语言设置 |
应用
yum
1 | yum check-update # 列出所有可更新的软件清单 |
使用国内yum源
1 | # 1. 备份原始源信息 |
阿里云与163源
CentOS7
http://mirrors.aliyun.com/repo/Centos-7.repo
http://mirrors.163.com/.help/CentOS7-Base-163.repo
CentOS6
http://mirrors.aliyun.com/repo/Centos-6.repo
http://mirrors.163.com/.help/CentOS6-Base-163.repo
CentOS5
离线安装
查看依赖包
1
yum deplist ansible
方案一: repotrack
1
2yum install -y yum-utils
reoptrack ansible方案二: yumdonwloader
1
2yum install -y yum-utils
yumdownloader --resolve --destdir=/tmp ansible仅会将主软件和基于当前操作系统缺失的依赖关系包一并下载
方案四: yum的downloadonly插件
1
2yum install -y yum-download
yum install -y ansible --downloadonly --downloaddir=/tmp仅会将主软件和基于当前操作系统缺失的依赖关系包一并下载
rpm 软件包管理
对于已安装软件
1 | rpm -qa | grep mysql # 查询 |
对于未按照软件包
1 | rpm -qip mysql-community-server-5.7.16-1.el7.x86_64.rpm # 查询软件包信息 |
安装升级删除
1 | rpm -ivh xx.rpm --test # 检查依赖关系, 不会真的安装 |
service
systemctl
init.d
journalctl
export
1 | export -p # 列出当前的环境变量值 |
其他
xargs
1 | cat file.txt | xargs # 所有内容单行输出 |
seq 生成连续的数字序列
1 | # 输出1到5 |
crontab 定时任务
-u user : 对指定用户的crontab服务进行处理
1 | * * * * * |
crontab的日志文件是/var/log/cron 查看cron服务状态systemctl status crond
注意
命令中
%是特殊字符, 需要加反斜线\转义脚本涉及到的文件路径要写全局路径
脚本用到java或其他环境变量时, 先通过
source命令引入1
2
3
4!/bin/sh
source /etc/profile
export RUN_CONF=/home/test/cbp.jboss.conf
/usr/local/jboss-4.0.5/bin/run.sh -c mev &当手动执行脚本OK, 但crontab不执行时, 很可能是环境变量的问题, 可尝试直接在crontab中引入环境变量
1
0 * * * * . /etc/profile;/bin/sh /home/test/restart.sh
每次任务执行完, 系统会将输出信息通过邮件发给当前用户, 可以通过忽略日志输出避免
1 | 0 * * * * /xx.sh > /dev/null 2>&1 |
新创建的定时任务不会马上执行, 至少要过2分钟, 但重启cron则马上执行. 当crontab失效时可以尝试/etc/init.d/crond restart解决问题. 可以查看日志/var/log/cron定位问题.
nohup
nohup 是 no hang up 的缩写,就是不挂断的意思。该命令可以在你退出帐户/关闭终端时忽略SIGHUP信号,从而继续运行相应的进程。在缺省情况下该作业的所有输出都被重定向到当前目录的nohup.out的文件中, 如果当前目录的 nohup.out 文件不可写,输出重定向到 $HOME/nohup.out 文件中。
1 | nohup java -jar xxx.jar > /dev/null 2>&1 & |
& 在后台运行,但是关闭shell后,对应的服务也会关闭,因为对SIGHUP信号不免疫。此时配合nohup可以让应用继续运行。 2>&1 是将标准出错重定向到标准输, /dev/null 2>&1 将标准输出和错误输出全部重定向到/dev/null中,也就是将产生的所有信息丢弃
系统监控
下面大部分命令属于sysstat软件包的一部分, 执行yum install -y sysstat
mpstat - cpu监控
每隔1s打印所有cpu使用情况, 间隔1s,打印10次
1 | [root@demo ~]# mpstat -P ALL 1 10 |
参数说明:
-P: ALL 或 0 - CPU个数-1 监控哪个cpu
结果说明:
1 | %user 在间隔的时间段里,用户态的CPU时间(%),不包含nice值为负进程 (usr/total)*100 |
vmstat 内存监控
1 | # 每秒1次, 输出3次 |
- procs 进程
- r 运行队列中进程数量
- b 等待IO的进程数量
- memory 内存
- swpd 使用虚拟内存大小
- free 可用内存大小
- buff 用作缓冲的大小
- cache 用作缓存的大小
- swap 交换区
- si 每秒从交换区写到内存的大小
- so 每秒写入到交换区的大小
- IO
- bi 每秒读取的块数 这里的块不同于文件系统的块, 是操作系统内部用于缓存和缓冲操作的, 当前大小为1024Bytes
- bo 每秒写入的块数
- system
- in 每秒中断数 包括时钟中断
- cs 每秒上下文切换数
- CPU
- us 用户进程执行时间
- sy 系统进程执行时间
- id 空闲时间, 包括IO等待时间
- wa 等待IO时间
- st 管理程序(hypervisor 虚拟化)为另一个虚拟进程提供服务而等待虚拟 CPU 的百分比
iostat IO监控
1 | $ iostat 1 3 |
CPU属性
- %user CPU在用户模式下的时间百分比
- %nice CPU在带NICE值的用户模式下的时间百分比
- %system CPU在系统模式下的时间百分比
- %iowait CPU等待输入输出完成的时间百分比
- %steal 管理程序维护另一个虚拟处理器时, 虚拟CPU的无意识等待时间百分比
- %idle CPU空闲时间百分比
%iowait值过高表示磁盘存在IO瓶颈; %idle值高表示CPU比较空闲; 如果%idle值高但系统响应慢, 可能是CPU等待内存分配; %idle持续低于10说明系统CPU处理能力不足
disk属性
- tps 设备每秒是IO请求数, 多个逻辑请求可能会被合并为一次IO请求, 一次IO请求的大小是未知的
- kB_read/s 每秒从设备读取的数据量
- kB_wrtn/s 每秒向设备写入的数据量
- kB_read 读取的数据总量
- kB_wrtn 写入的数据总量
1 | # 显示更详细的io信息 |
rrqm/s 每秒进行 merge 的读操作数目。即 rmerge/swrqm/s 每秒进行 merge 的写操作数目。即 wmerge/sr/s 每秒完成的读 I/O 设备次数。即 rio/sw/s 每秒完成的写 I/O 设备次数。即 wio/srsec/s 每秒读扇区数。即 rsect/swsec/s 每秒写扇区数。即 wsect/srkB/s 每秒读K字节数。是 rsect/s 的一半,因为每扇区大小为512字节。wkB/s 每秒写K字节数。是 wsect/s 的一半。avgrq-sz 平均每次设备I/O操作的数据大小 (扇区)。avgqu-sz 平均I/O队列长度。await 平均每次设备I/O操作的等待时间 (毫秒)。r_await 平均每次设备读I/O操作的等待时间 (毫秒)。w_await 平均每次设备写I/O操作的等待时间 (毫秒)。svctm 平均每次设备I/O操作的服务时间 (毫秒)%util 一秒中有百分之多少的时间用于 I/O 操作,即被io消耗的cpu百分比
如果 %util 接近 100%,说明产生的I/O请求太多,I/O系统已经满负荷,该磁盘可能存在瓶颈。如果 svctm 比较接近 await,说明 I/O 几乎没有等待时间;如果 await 远大于 svctm,说明I/O 队列太长,io响应太慢,则需要进行必要优化。如果avgqu-sz比较大,也表示有大量io在等待。
pidstat - 进程资源占用监控
pidstat 是sysstat软件套件的一部分, CentOS使用该命令安装: yum install sysstat
常用参数
-u默认参数,显示各个进程的 CPU 统计信息-r显示各个进程的内存使用情况-d显示各个进程的 IO 使用-w显示各个进程的上下文切换
显示所有进程的CPU使用信息, pidstat 或 pidstat -u -p ALL
1 | $ pidstat |
PID 进程ID%usr 进程在用户空间占用cpu的百分比 %system 进程在内核空间占用cpu的百分比%guest 进程在虚拟机占用cpu的百分比%CPU 进程占用cpu的百分比CPU 处理进程的cpu编号Command 当前进程对应的命令
查看内存
1 | $ pidstat -r -p 1205 |
PID 进程标识符Minflt/s 任务每秒发生的次要错误,不需要从磁盘中加载页Majflt/s 任务每秒发生的主要错误,需要从磁盘中加载页VSZ 虚拟地址大小,虚拟内存的使用KBRSS 常驻集合大小,非交换区五里内存使用KBCommand 当前进程对应的命令
查看io
1 | $ pidstat -d -p 1205 |
PID 进程idkB_rd/s 每秒从磁盘读取的KBkB_wr/s 每秒写入磁盘KBkB_ccwr/s 任务取消的写入磁盘的KB。当任务截断脏的pagecache的时候会发生Command 当前进程对应的命令
查看上下文切换
1 | $ pidstat -w -p 4846 |
PID 进程idCswch/s 每秒主动任务上下文切换数量Nvcswch/s 每秒被动任务上下文切换数量Command 当前进程对应的命令
查看线程信息
1 | $ pidstat -t -p 4846 |
PID 进程ID%usr 进程在用户空间占用cpu的百分比 %system 进程在内核空间占用cpu的百分比%guest 进程在虚拟机占用cpu的百分比%CPU 进程占用cpu的百分比CPU 处理进程的cpu编号Command 当前进程对应的命令
sar - 系统活动报告
统计结果可以输出到文件
1 | sar -o sarfile.log -u 1 3 |
ucpu使用率qcpu负载B内存使用率R内存页Sswap使用率bion网络d块设备F挂载设备m电源管理
CPU使用率
1 | $ sar -u 1 3 |
CPU: all表示统计的所有CPU%user: 用户级运行cpu占比 %nice:用户级别用于nice操作CPU占比 %system: 核心级运行CPU占比%iowait: 用于等待IO操作占用CPU时间的百分比%steal: 管理程序(hypervisor 虚拟化)为另一个虚拟进程提供服务而等待虚拟 CPU 的百分比%idle: 显示CPU空闲占比, 若%iowait过高则表示磁盘存在IO瓶颈; 若%idel高但系统响应慢则可能是内存不足, cpu在等待分配内存; 若%idle持续<1则系统cpu处理能力不足
内存使用率
1 | $ sar -r 1 3 |
kbmemfree: 可用内存, 不含buffer/cache kbmemused: 已用内存, 包含buffer/cache%memused: kbmemused占总内存百分比kbbuffers: buffer空间大小 kbcached:cache空间大小kbcommit: 为了确保不溢出而需要的内存(RAM + swap) %commit: kbcommit占比kbactive: 最近使用的不被回收的 kbinact: 不经常使用的容易被回收 kbdirty: 赃页,等待写入磁盘
CPU负载
1 | $ sar -q 1 3 |
runq-sz: 运行队列长度, 即等待运行的进程数plist-sz: 进程列表中进程和线程的数量ldavg-1 ldavg-5 ldavg-15 : 过去1/5/15分钟系统的平均负载blocked: 正在等待io的任务数量
内存页状态
1 | $ sar -B 1 3 |
pgpgin/s pgpgout/s : 每秒从磁盘换入/出到内存的字节数(KB)fault/s: 每秒系统产生的缺页数, 即major+minor; majflt/s: 每秒产生的主缺页数pgfree/s: 每秒被放入空闲队列的页个数 pgscank/s: 每秒被kswapd扫描的页数pgscand/s: 每秒直接被扫描的 pgsteal/s: 每秒从cache中被清除用来满足内存需要的页数%vmeff: 每秒清除的页(pgsteal)占总扫描页(pgscank+pgscand)
swap信息
1 | $ sar -W 1 3 |
pswpin/s pswpout/s : 每秒换入/出的交换页面(swap page)数量
IO和传输速率
1 | $ sar -b 1 3 |
tps: 每秒物理设备的IO请求总数rtps wtps: 每秒读/写物理设备的io请求数bread/s bwrtn/s: 每秒读写物理设备的数据量, 单位: 块/s, 这里的块等于扇区, 所有大小为512Bytes
文件系统的块大小可以通过blockdev --getbsz /dev/vda或者 stat -f /dev/vda 查看(块是文件系统里的概念, 扇区(fdisk- l)是磁盘里的概念, 一般块是扇区的2^n倍)
块设备信息
1 | $ sar -d 1 3 |
tps: 每秒请求物理磁盘的次数, 多个逻辑请求会被合并成1个io请求, 一次传输的大小是不确定的rd_sec/s wr_sec/s : 每秒读写的扇区数量, 扇区大小512Bytesavgrq-sz : 平均每次io请求的扇区大小avgqu-sz : 磁盘请求队列的平均长度await: 从请求磁盘操作到系统完成处理, 每次请求的平均消耗时间(毫秒), 包括请求队列等待时间svctm : 系统处理每次请求的平均时间(毫秒), 不包括在请求队列中消耗的时间%util: I/O请求占CPU的百分比, 比率越大, 说明设备带宽使用率越高
网卡流量
-n参数有6个开关:
- DEV显示网络接口信息。
- EDEV显示关于网络错误的统计数据。
- NFS统计活动的NFS客户端的信息。
- NFSD统计NFS服务器的信息
- SOCK显示套接字信息
- ALL显示所有5个开关
1 | $ sar -n DEV 1 2 |
IFACE :LAN接口rxpck/s txpck/s :每秒钟接收/发送的数据包rxkB/s txkB/s:每秒钟接收/发送的字节数 千字节/srxcmp/s txcmp/s :每秒钟接收/发送的压缩数据包rxmcst/s :每秒钟接收的多播数据包
统计网络设备通信失败信息
1 | $ sar -n EDEV 1 3 |
结果
rxerr/s txerr/s :每秒钟接收/发送的坏数据包:每秒钟的坏数据包coll/s :每秒冲突数rxdrop/s txdrop/s :因为缓冲充满,每秒钟丢弃的已接收/发送数据包数txcarr/s :发送数据包时,每秒载波错误数\rxfram/s :每秒接收数据包的帧对齐错误数rxfifo/s txfifo/s :接收/发送的数据包每秒FIFO过速的错误数
IP层统计
1 | $ sar -n IP 1 3 |
IP层错误统计
1 | $ sar -n EIP 1 3 |
TCP连接信息
1 | $ sar -n TCP 1 3 |
active/s : 新的主动连接 passive/s : 新的被动连接iseg/s : 接受的段 oseg/s : 输出的段
TCP层错误统计
1 | $ sar -n ETCP 1 3 |
atmptf/s : 每秒重试失败数 estres/s : 每秒断开连接数
retrans/s : 每秒重传数 isegerr/s : 每秒错误数 orsts/s : 每秒RST数
socket连接信息
1 | $ sar -n SOCK 1 3 |
totsck : 当前被使用的socket总数tcpsck : 当前正在被使用的TCP的socket总数udpsck : 当前正在被使用的UDP的socket总数rawsck : 当前正在被使用于RAW的skcket总数if-frag : 当前的IP分片的数目tcp-tw : TCP套接字中处于TIME-WAIT状态的连接数量
pstack 跟踪进程堆栈
pstack 命令必须由相应进程的属主或 root 运行, 可以使用 pstack 来确定进程挂起的位置, 可以在一段时间内,多执行几次pstack,若发现代码栈总是停在同一个位置,那个位置就需要重点关注,很可能就是出问题的地方
1 | $ pstack 4846 |
strace 跟踪进程的系统调用
1 | $ strace cat /dev/null |
free 查询可用内存
1 | free -h |
fdisk 磁盘列表
1 | $ fdisk -l |
df 查询磁盘可用空间
1 | $ df -lh |
du 磁盘使用统计
1 | # 统计当前目录下各文件/目录占用磁盘大小 |
iftop 带宽使用监控
mtr 网络测试工具
mtr(My traceroute)几乎是所有Linux发行版本预装的网络测试工具,集成了tracert与ping这两个命令的图形界面,功能十分强大。ping送出封包到指定的服务器。如果服务器有回应就会传送回封包,并附带返回封包来回的时间。tracert返回从用户的电脑到指定的服务器中间经过的所有节点(路由)以及每个节点的回应速度。
mtr默认发送ICMP数据包进行链路探测,通过“-u”参数指定UDP数据包用于探测。相对于traceroute只做一次链路跟踪测试,mtr会对链路上的相关节点做持续探测并给出相应的统计信息。mtr能避免节点波动对测试结果的影响,所以其测试结果更正确,建议优先使用。
1 | jcy-dev (0.0.0.0) Fri Feb 26 09:48:16 2021 |
常见可选参数说明
- -r或–report:以报告模式显示输出。
- -p或–split:将每次追踪的结果分别列出来,而非–report统计整个结果。
- -s或–psize:指定ping数据包的大小。
- -n或–no-dns:不对IP地址做域名反解析。
- -a或–address:设置发送数据包的IP地址。用于主机有多个IP的情况。
- -4:只使用IPv4协议。
- -6:只使用IPv6协议。
在mtr运行过程中,您也可以输入相应字母来快速切换模式,各字母的含义如下。
- ?或h:显示帮助菜单。
- d:切换显示模式。
- n:切换启用或禁用DNS域名解析。
- u:切换使用ICMP或UDP数据包进行探测。
返回结果说明
默认配置下,返回结果中各数据列的说明如下。
- 第一列(Host):节点IP地址和域名。按 n 键可切换显示。
- 第二列(Loss%):节点丢包率。
- 第三列(Snt):每秒发送数据包数。默认值是10,可以通过“-c”参数指定。
- 第四列(Last):最近一次的探测延迟。
- 第五、六、七列(Avg、Best、Worst):分别是探测延迟的平均值、最小值和最大值。
- 第八列(StDev):标准偏差。越大说明相应节点越不稳定。
分析链路测试结果
结合Avg(平均值)和StDev(标准偏差),判断各节点是否存在异常。
若StDev很高,则同步观察相应节点的Best和Worst,来判断相应节点是否存在异常。
若StDev不高,则通过Avg来判断相应节点是否存在异常。
注意:上述StDev高或者不高,并没有具体的时间范围标准。而需要根据同一节点其它列的延迟值大小来进行相对评估。比如,如果Avg为30ms,那么,当StDev为25ms,则认为是很高的偏差。而如果Avg为325ms,则同样的StDev为25ms,反而认为是不高的偏差。
查看节点丢包率,若“Loss%”不为零,则说明这一跳路由的网络可能存在问题。导致节点丢包的原因通常有两种。
- 人为限制了节点的ICMP发送速率,导致丢包。
- 节点确实存在异常,导致丢包。
确定当前异常节点的丢包原因。
若随后节点均没有丢包,说明当前节点丢包是由于运营商策略限制所致,可以忽略。如前文链路测试结果示例图中的第2跳路由的网络所示。
若随后节点也出现丢包,说明当前节点存在网络异常,导致丢包。如前文链路测试结果示例图中的第5跳路由的网络所示。
说明:前述两种情况可能同时发生,即相应节点既存在策略限速,又存在网络异常。对于这种情况,若当前节点及其后续节点连续出现丢包,而且各节点的丢包率不同,则通常以最后几跳路由的网络的丢包率为准。
通过查看是否有明显的延迟,来确认节点是否存在异常。通过如下两个方面进行分析。
若某一跳路由的网络之后延迟明显陡增,则通常判断该节点存在网络异常。如前文链路测试结果示例图所示,从第5跳路由的网络之后的后续节点延迟明显陡增,则推断是第5跳路由的网络节点出现了网络异常。
注:高延迟并不一定完全意味着相应节点存在异常,延迟大也有可能是在数据回包链路中引发的,建议结合反向链路测试一并分析。
ICMP策略限速也可能会导致相应节点的延迟陡增,但后续节点通常会恢复正常。